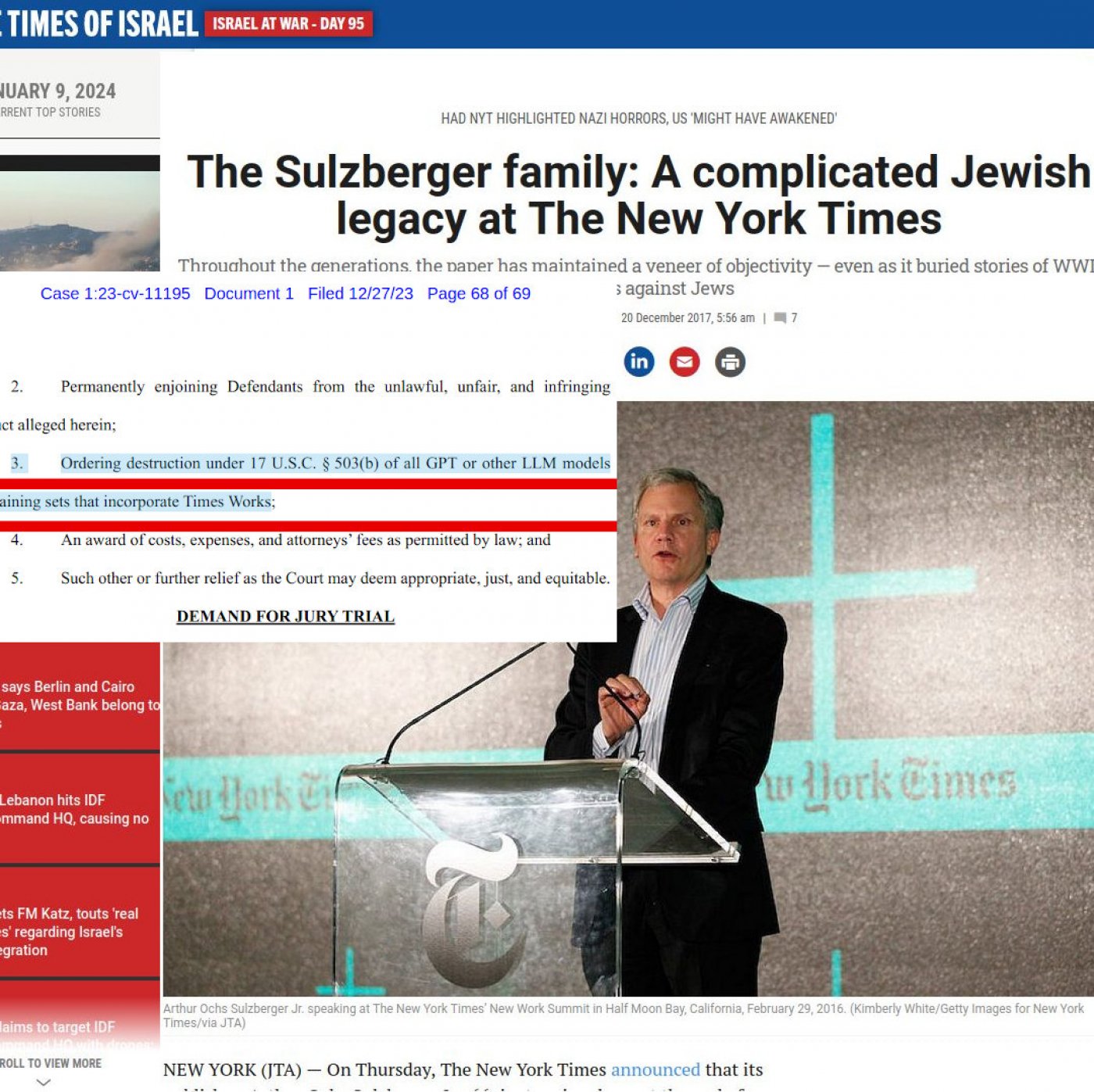
Искане за: "Разпореждане за унищожаване съгласно 17 U.S.C. § 503(b) на всички GPT или други LLM модели, които включват творби на NYT."
("Ordering destruction under 17 U.S.C. § 503(b) of all GPT or other LLM models and training sets that incorporate Times Works")
Здравейте приятели, за света на Изкуствения Интелект новата 2024 година започна наистина доста интересно.
В края на миналата 2023-та година NYT започна дело срещу OpenAI с няколко конкретни искания.
Едно от исканията на NYT записано под точка 3 от исканията им е унищожаването на цитирам: "вички GPT или други LLM модели".
Другите искания разбира се са за много пари ... Ха ха ха, ясно е нали?
В съдебният иск NYT обвинява OpenAI в използване на авторски защитени статии на NYT в обучението на ChatGPT без подходящо разрешение или компенсация.
Официално съдебния иск е започнат от ищеца NYT след Неуспешни Преговори с OpenAI.
От коментарите от страна на OpenAI обаче става ясно, че преди подаването на иска, между OpenAI и NYT са били проведени месеци на неуспешни преговори за споразумение за лицензиране на съдържанието.
OpenAI споделят, че още през лятото изрично са предоставили на издателите включително и на NYT цитирам: "механизъм за отказ от съдържание".
Механизъм, който изрично и е бил приет от NYT още в месец Август 2023 г.
Според този механизъм издателите могат да подават информация към OpenAI за изключване на съдържание, което е тяхна интелектуална собственост от използване за обучение на ChatGPT или други LLM модели на Изкуствен Интелект.
Какво всъщност означава LLM модели?
Под "LLM модели" се разбира "Large Language Models".
Декодирано и преведено това са големи модели на изкуствен интелект, специализирани в обработката на език.
Тези модели са обучени върху огромни количества текстови данни и могат да извършват различни задачи свързани с обработката на естествен език, като генериране на текст, разбиране на езика, преводи и отговаряне на въпроси.
ChatGPT, който е разработен от OpenAI е пример точно за такъв LLM модел.
На линка в сайта на подкаста Дух в Черупка: Подкаст с Lupo можете да се запознаете с пълния текст на съдебния иск на NYT към OpenAI: NYT_Complaint_Dec2023.pdf
По-интересното обаче в случая, е че на 8 Януари 2024 г в блога на OpenAI има и официален отговор към обвиненията на NYT.
Заглавието на блог поста е: "OpenAI и журнализма". (Линка към този пост също е достъпен в сайта на подкаста Дух в Черупка: Подкаст с Lupo.)
С оригиналния пълен текст на отговора можете да се запознаете от техния пост, тук в подкаста по-долу накратко ще обобщя за какво става дума в този отговор:
Цитирам:
"Целта ни е да разработим инструменти с Изкуствен Интелект, които да помагат на хората да решават проблеми, които иначе биха били недостижими.
Хора по целия свят вече използват нашата технология за подобряване на ежедневието си.
Милиони разработчици и повече от 92% от компаниите от списъка Fortune 500 днес разработват на база на нашите продукти.
Въпреки, че не сме съгласни с твърденията в иска на "Ню Йорк Таймс", ние го разглеждаме като възможност да изясним нашия бизнес, нашите намерения и начина, по който изграждаме нашата технология.
Нашата позиция може да бъде обобщена в следните четири точки, които разясняваме по-долу:
- Ние си сътрудничим с новинарски организации и създаваме нови възможности.
- Обучението е в рамките на честната употреба (fair use), но ние предоставяме механизъм за отказ (opt-out), защото това е правилното действие.
- "Повтарянето" е рядък проблем, по който работим, за да го намалим до нула.
- "Ню Йорк Таймс" не разказва пълната история."
Приятели за да бъде всичко максимално ясно, тук бих искал да започна с изричното да обяснение на термините от т 2:
Обучението е в рамките на честната употреба (fair use), но ние предоставяме механизъм за отказ (opt-out), защото това е правилното действие.
Обяснявам и двата термина в подробности, защото лично на мен ми се наложи да прочета и за двата термина изрично, за да съм сигурен, че разбирам за какво точно става въпрос ... :)
1. "Честна употреба" (fair use):
Това е юридически термин, особено в контекста на американското законодателство, който позволява ограниченото използване на защитено с авторски права съдържание без изрично разрешение от собственика на авторските права.
Честната употреба (fair use) включва, но не се ограничава до: критика, коментар, новинарско отразяване и изследвания.
В контекста на AI, това конкретно означава, че OpenAI вярва, че използването на общодостъпни данни за обучение на своите модели е законно и не нарушава авторските права.
2. "Предоставяме възможност за отказ" (we provide an opt-out):
Това означава, че компанията предоставя механизъм, който позволява на издателите да изберат и посочат свое съдържание, над което имат интелектуална собственост да НЕ бъде използвано от AI системата за обучение.
Конкретно този избор е предложен от OpenAI на издателите като част от добрия бизнес етикет и уважение към правата на собствениците на съдържание.
Например, ако издател не желае техни статии да бъдат част от базата данни, използвана за обучение на AI, те могат да уведомят компанията и тя ще премахне тези данни от своите обучителни набори.
И така явно според някои самозабравили се медийни гиганти използването на публично достъпни източници на информация било незаконно?
Това е така, поне според това което аз разбирам ... OpenAI открито заявяват, че използването на публично достъпна информация НЕ е незаконно.
Публично достъпна информация ... определено според мен публично достъпната информация НЕ може да е проблем ... не мислите ли приятели?
Публично достъпната информация мисля е съвсем нормално да се предполага че е достъпна за всички и никой чичко не би трябвало да може след време да ни съди за това че сме прочели някаква статия публикуваната от него? ... Нали?
Това се очаква да е така каквито и безумни драконовски закони за защита на авторските права и съдържанието да се имат в предвид ...
Не мислите ли и вие така приятели или аз нещо не ги разбирам и принципно нещата и фундаментално греша? :)
Нека сега обаче да се заемем са най-интересната точка 4 от твърденията на OpenAI:
Ню Йорк Таймс" НЕ разказва пълната история
Според OpenAI :
"Дискусиите ни с "Ню Йорк Таймс" изглеждаха, че напредват конструктивно до нашата последна комуникация на 19 декември.
Преговорите се фокусираха върху партньорство с висока стойност около реалното време на показване с признание в ChatGPT, в което "Ню Йорк Таймс" щеше да получи нов начин да се свърже със съществуващите и нови читатели, а нашите потребители - достъп до тяхната журналистика.
Обяснихме на "Ню Йорк Таймс", че тяхното съдържание не допринася значимо за обучението на нашите съществуващи модели и също така няма да има значимо въздействие за бъдещото обучение.
Техният иск от 27 декември, за който научихме като прочетохме "Ню Йорк Таймс", дойде като изненада и разочарование за нас."
Да, нещата ставеат все по-интересни ... доста интересно, определено!
Какво става дефакто ясно ...
OpenAI си били сътрудничели активно с NYT.
Заедно разработват някакви си механизми за сътрудничество ... НО междувременно правят грешката и ясно дават да се разбере на NYT, че тяхното интелектуално съдържание всъщност НЯМА някаква особена СТОЙНОСТ като източник за информация.
И поради тази причина едва ли ще бъде използвана за обучението на LLM моделите на OpenAI ... ха ха ха
Демек в прав текст им казват интелектуалната ви собственост за която толкова дигате пара наляво надясно и тръбите нагоре надолу не е от особен интерес за нас и за LLM моделите ни Изкуствен интелект.
Поне от това е което аз разбирам от цялата ситуация.
След като NYT разбират, че OpenAI НЯМАТ ама абсолютно никакво намерение да им даде нищо и няма да изкара нито цент от OpenAI NYT решават да включат тежката артилерия и мастите си адвокати.
На 29 Декември NYT завеждат делото за компенсации и по-важното за унищожаването на цитирам: "всички GPT или други LLM модели".
Мда ... определено "приятелчетата" от NYT имат опит и добре знаят правилата на мръсната игра.
Явно покрай интереса и напредъка на OpenAI на собствениците на NYT им е замирисало на доларчета и злато и най-вероятно NYT нямат никакво намерение да се откажат без поне да се опитат да отмъкнат някакво солидно тлъсто парче от баницата.
Тук обаче има още нещо много важно което трябва да изясним преди да стигнем до последната точка в тази сага
Официално според OpenAI, както и според повечето активни професионални потребители на ChatGPT цитираните от NYT примери за уж повтарянето и цитирането на части от текстове на статиите на NYT от страна на ChatGPT е невъзможно.
Тук мненията на всички GPT експерти са еднакви: NYT безсрамно лъжат и манипулират представената от тях информация.
Те НЕ дават пълен и цялостен достъп до целия промпт, не дават достъп до историята на сесията и инструкции и историята на конкретната комуникация, която те имат с ChatGPT, преди той модела на ИИ да започне да повтаря почти буквално части от техни статии.
За да се постигне подобна форма на "цитиране" и "повтаряне" определено модела на Изкуствен Интелект трябва да е предварително инструктиран да го направи.
Дали това са Поредните Манипулации и плитки Лъжи от страна на NYT?
Най-вероятно да ...
Лично според мен цялото това гръмко съдебно дело е поредния правен фарс.
Много шум за нищо ...
Приятели, за да си обясним веднъж за винаги защо се случва всичко това определено трябва да разберем кой точно е собственика прикрит за адвокатите на ищеца NYT ...
КОЙ дефакто стои за NYT? Кой е собственика на NYT?
Компанията "Ню Йорк Таймс", която издава вестник "Ню Йорк Таймс", в момента е собственост и се контролира от семейство Сълцбeргер, което я притежава от няколко поколения насам.
Семейство Сълцбeргер са доста богат и известен еврейски клан от задкулисната върхушка управляваща САЩ от десетилетия ...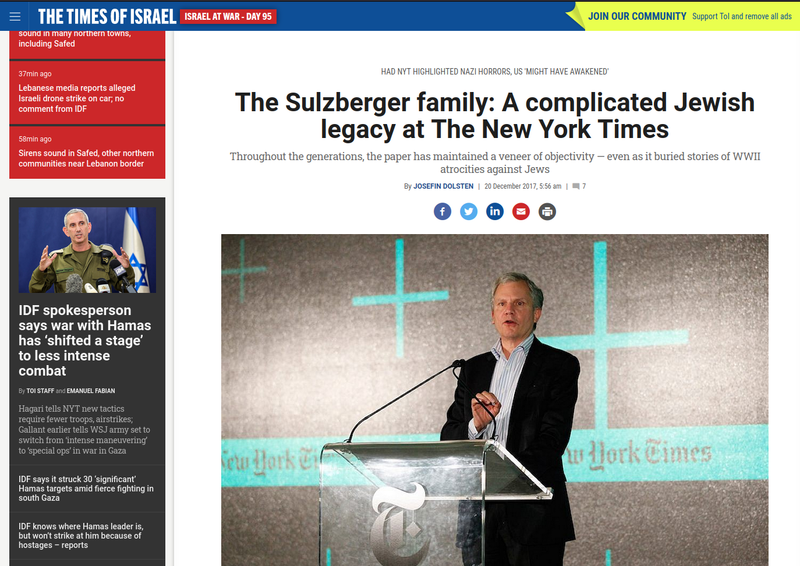
Настоящият председател на Компанията "Ню Йорк Таймс" и издател на вестника е А. Г. Сълцбергер.
Той е шестият член на семейство Охс - Сълцбергер, който заема длъжността издател откакто вестникът е закупен от Адолф Охс през 1896 година.
Компанията работи с два вида акции, при която акциите от клас А се търгуват публично, а акциите от клас В се държат на закрито.
Приятели имайте в предвид, че акциите клас B са тези акции с реален глас и права в управлението на компанията.
Семейство Сълцбергер притежава мнозинството от въпросните акции клас В, което им дава значителен контрол над компанията.
А. Г. Сълцбъргер лично притежава само 1,4% от акциите от клас А и цели 94,5% от акциите от клас В.
Тази структура гарантира, че семейството запазва пълния си контрол, особено по отношение на решенията на борда, тъй като акционерите от клас В имат правото да избират повече директори за борда в сравнение с акционерите от клас А.
"Таймс" има разнообразни източници на приходи, като значителна част идват от абонаментите.
През 2022 година компанията генерира 2,3 милиарда долара приходи, като 67% от тях са от абонаменти.
Моделът, базиран на абонаменти, е станал значителна част от техния бизнес, особено с растежа на цифровите абонаменти.
Заключение
Приятели, явно това гръмко съдебно дело е поредния повод да се замислим сериозно за бъдещето на Изкуствения Интелект особено на този ИИ.
Да, по-горе в изложението на историята съзнателно пропуснах един важен факт, че делото на NYT не е само срещу OpenAI, но и срещу основния им инвеститор и спонсор Micro$oft.
Честно казано грам НЕ ми пука за Micro$oft и горе долу също толкова ми пука и за OpenAI ... гарван гарвано око НЕ вади.
И Сам Алтман и тия от семейството Сълцбeргер са от едно племе, ще се разберат, в най-лошия случай ще си разменят някой друг долар и керавана им ще продължи да си върви.
В целия този конфликт лично според мен има къде по-важно нещо.
Нека не забравяме все пак че ChatGPT е LLM модел на ИИ с изцяло затворен код.
Да, всичко това все пак е поредната черна кутия въпреки силно подвеждащото "Open" в името на фирмата, която седи зад него: OpenAI.
Тук обаче искам да поясня нещо много важно!
Лично аз ежедневно използвам в работата си ChatGPT.
Лично за мен ChatGPT е изключително ценен помощник в работата ми.
ChatGPT е професора експерт по почти всяка интересуваща ме тема, който срещи 20$ месечно е на разположение 24 в денонощието.
И срещи тези най-добре инвестирани от мен $20 получавам почти винаги правилния и точния съвет и вярното решение на задачата пред която съм изправен за разрешаване.
Определено не мисля, че въобще някой някога ще бъде в състояние да спре развитието и навлизането в света ни Изкуствения Интелект.
Духа вече е пуснат от бутилката ... НЯМА връщане обратно назад!
Не съм сигурен, че това е кутията на Пандора, както някой апокалиптични анализатори се изказват и интерпретират Изкуствения Интелект ...
Да, абсолютно ясно обаче е че в един момент добрия Дух от бутилката в неправилните ръце използван по неправилен начин може от днес за утре да се превърне в кутията на Пандора ... ФАКТ!
Както и да е 100% нека да оставим тези теории и да се върнем към днешния проблем.
Аз лично не мисля че днес има някой, дори и сред свръх богатите евреи дърпащи конците в Америка, дори и сред тях вече няма такъв, който да е в състояние да спре развитието и навлизането на Изкуствения Интелект.
Даже и подобни супер богати и влиятелни американски еврейски кланове каквито са тия от въпросното семейство Сълцбергер, едни от многото спотайващи се в сенките на властта.
Нека пак да си поговорим за LLM Моделите на Изкуствен Интелект с Отворен код
Лично за мен това конкретно дело е още един нагледен пример за това, колко жизнено и изключително важно е активното разработване на моделите на Изкуствен Интелект с ОТВОРЕН КОД.
Да, ясно е че когато става въпрос за LLM модели с отворен код тук НЕ може и дума да става за парите и средствата, необходими за обучението на един LLM модел като GPT-4.
Но нека да не забравяме, че вече има доста алтернативи на GPT-4, които използват технологии които изискват десетки пъти по-малко средства и ресурси за да достигнат нивото на ChatGPT ...
И така Приятели в днешния епизод на подкаста Дух в Черупка в основи разгледахме сложния и многопластов съдебен спор между OpenAI и NYT.
От една страна, стои въпроса за законността - до къде точно се простират границите на 'честната употреба' в контекста на Изкуствения интелект?
Как този съдебен случай и другите като него могат и ще реформират правните рамки, които уреждат авторските права в дигиталната ера.
От друга страна, стои етичният аспект за авторството, който е не е по-малко важен.
Как компании като OpenAI ще успеят да балансират иновациите с пречките и рамките спрямо интелектуалната собственост?
Определено законите трябва да бъдат преработени и съобразени с новите реалности на 21 век.
Необходимо е да се намери златната среда между поддържането на свободата за иновациите форма на коректност и честност към двете страни, когато става въпрос за защитата на правата на авторите.
Този случай отваря много въпроси относно бъдещето на AI и медийната индустрия.
Едно обаче е съвсем сигурно и ясно!
Живеем във времена, когато технологиите се развиват със супер бързи темпове.
От решаващо значение е всичките тези закони за интелектуалната собственост максимално бързо да се преработят така, че да НЕ са пречка пред прогреса.
Явно балансът между иновацията и защитата на интелектуалната собственост е темата, която тепърва ще продължава да предизвиква дебати и да формира бъдещето на нашето общество.
Приятели, благодаря ви че изслушахте до край този подкаст епизод.
Ако ви допадат темите разглеждани тук обмислете възможността да се абонирате за подкаста в YouTube и в Spotify.
Задължително оставете коментар! Очаквам коментарите ви по темата с голям интерес!
Чета всички коментари и отговарям на болшинството от тях!
Аз съм Lupo и ви желая Късмет!
И карай да е весело!